The Best System for Rating Schools: Families
Deciding what a rating system should measure isn’t as easy a process as it may seem, and it becomes more difficult the bigger the group being measured and the more diverse the audience who will rely on the scores. For that reason, I’m almost tempted to get into the weeds of a pedantic argument with Erika Sanzi’s complaint about the rating system that Rhode Island is currently using for its public schools:
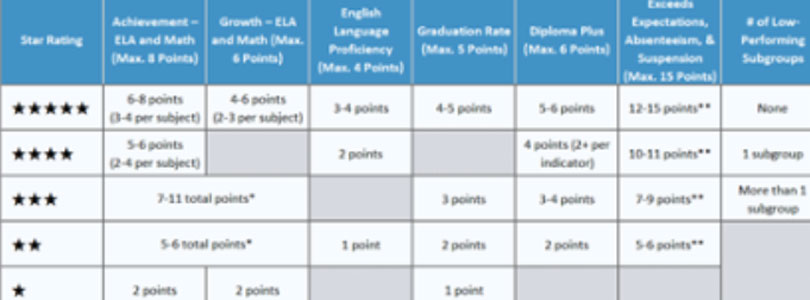
Rhode Island’s system for rating school quality by assigning them between one and five stars is fundamentally flawed. Why? It holds white affluent schools to a lower standard than schools that serve high numbers of low-income English language learners. One of the categories on which schools are judged only applies to some schools and they aren’t the ones in the most cost-prohibitive leafy green suburbs or the only Providence school that requires an exam in order to be admitted. Schools that do not serve a significant number of low- income students, nonwhite students or students with limited English proficiency automatically get a pass—they earn overall ratings of 4 and 5 stars despite never having to prove that they can successfully serve higher need populations. Does it make sense to celebrate that?
Well, does it make sense to rate schools on their theoretical ability to serve a population that they do not serve? If not, the line has to be drawn somewhere. At what size population of students does it make sense to judge them as a unique category being served by the school? In the “leafy green suburbs,” for example, minority students do count toward a school’s overall scores, but they aren’t separated out into their own category.
Part of the problem when it comes to measuring education is that, to a greater degree than in most of our institutions, we’ve come to see measurement as a value judgment more than an assessment. Maybe that has to do with the fact that it involves our children and our sense of their future, as if declaring a school to be under-performing forever brands its current students as under-educated. Some of the reluctance to ratings is probably also mixed up in modern grievance sensibility. And surely the institutional biases of unions and bureaucracy create a general aversion to assessment.
The bigger problem, however, is the implicit purpose of the testing. The experts purport to put out this universal measure of comparison. In this, schools’ special interests have a point: It is impossible to capture the value of a school this way. Evaluations such as for Blue Ribbon schools or private school accreditation are extensive processes that couldn’t possibly be done at every school every year.
If the extent of accountability were merely that all students took a standardized test and the results were published, then we could be frank about the limited scope of the results. We would understand that there are mitigating circumstances for a lower-performing school in a poor community in which English is largely a second language, while suburban parents who thought they’d bought into high-performing districts would have something to go by. In all districts, the schools would make their cases to their customers, with different schools’ highlighting different things.
Then it could be up to families — empowered with educational freedom — to determine whether they are receiving value beyond what the test scores suggest.
With the judgment of families in mind, Rhode Island’s still-new (and ridiculously confusing) star system puts the spotlight on something that isn’t included: feedback. If we’re interested in capturing the real value residing in our schools, why is there no component on the scorecard for family satisfaction?
It is as if the education establishment doesn’t trust what its customers will say if they’re given a forum of consequence in which to express their opinions. A more-subtle point may be more significant: An ostensibly objective rating system allows the supposed experts to tell families what to value. But the people making the metrics want to tell people how good schools are, not ask them.


